

ChatGPT Search SEO: Jak sprawić, żeby Twoja strona była odkrywalna, wiarygodna i cytowana w AI Search
Większość strategii SEO powstała w świecie, w którym wyszukiwanie oznaczało Google, widoczność oznaczała pozycje w rankingu, a sukces mierzono liczbą kliknięć.
Ten świat nadal istnieje - ale nie obejmuje już całej ścieżki wyszukiwania.
W 2026 roku coraz więcej researchu produktowego, porównań dostawców i decyzji zakupowych odbywa się wewnątrz konwersacyjnych systemów AI: ChatGPT Search, Perplexity, Google AI Overviews i AI Mode. Te systemy nie zwracają po prostu dziesięciu niebieskich linków. Odpowiadają, podsumowują, porównują i często cytują źródła.
To zmienia pytanie, które każda marka musi sobie zadać.
Nie tylko: „Czy rankujemy na pierwszej stronie?"
Ale też: „Czy jesteśmy źródłem, które system AI może znaleźć, zrozumieć, uznać za wiarygodne i zacytować?"
Ten przewodnik wyjaśnia, jak zoptymalizować stronę pod ChatGPT Search i AI Search w 2026 roku - bez udawania, że istnieje tajny wzór rankingowy. Nie ma gwarantowanego sposobu na pojawienie się w każdej odpowiedzi AI. Istnieją jednak jasne, kontrolowalne sygnały, które sprawiają, że strona jest łatwiej pobieralna, przypisywalna i cytowalna w różnych środowiskach AI Search.
Te sygnały są fundamentem optymalizacji pod AI Search.
Dlaczego AI Search zmienia ścieżkę wyszukiwania
Wiele systemów AI Search korzysta z mechanizmów opartych na pobieraniu treści: identyfikują odpowiednie źródła internetowe, wyodrębniają użyteczne fragmenty i syntetyzują je w odpowiedź. AI Search nie zachowuje się jak klasyczna lista wyników rankingowych. Zamiast tego często wybiera i podsumowuje źródła przydatne do odpowiedzi na konkretne pytanie.
Wewnętrzna mechanika każdego systemu jest różna i żaden z głównych dostawców nie publikuje kompletnej listy wymagań optymalizacyjnych. Możemy jednak stwierdzić z przekonaniem, że pewne właściwości treści i architektury strony sprawiają, że strony są łatwiej pobieralne, przypisywalne i cytowalne - niezależnie od tego, który system AI Search dokonuje selekcji.
Optymalizacja pod AI Search nie polega na manipulowaniu modelem. Polega na redukowaniu niejednoznaczności dla systemów, które pobierają, podsumowują, przypisują i cytują informacje z internetu.
Czym optymalizacja pod AI Search nie jest
Optymalizacja pod AI Search nie jest manipulowaniem promptami. Nie jest upychaniem słów kluczowych dla modeli językowych. Nie jest gwarantowanym sposobem na pojawienie się w każdej odpowiedzi ChatGPT, Perplexity czy Google AI Overview. I nie zastępuje SEO.
Jest dyscypliną wykrywalności w nowym środowisku wyszukiwania.
Celem jest sprawienie, żeby strona była łatwiejsza dla systemów AI do:
- crawlowania
- interpretowania
- przypisywania
- weryfikowania
- podsumowywania
- cytowania
Wymaga to solidnego technicznego SEO, przejrzystej architektury treści, danych strukturalnych, spójności encji, twierdzeń opartych na źródłach i mierzalnego punktu bazowego widoczności.
Optymalizacja pod AI Search nie jest skrótem omijającym SEO. Jest kolejną warstwą zbudowaną na jego fundamencie.
Co wiemy - i co pozostaje niejasne
Żaden z głównych dostawców AI Search nie publikuje kompletnego wzoru rankingowego ani cytowania. ChatGPT Search, Perplexity oraz Google AI Overviews i AI Mode korzystają z różnych systemów, indeksów, crawlerów, modeli i zachowań cytowania.
Oznacza to, że optymalizacja pod AI Search nie powinna być przedstawiana jako inżynieria wsteczna jednego algorytmu.
To, co możemy zweryfikować na podstawie oficjalnej dokumentacji, jest węższe, ale nadal strategicznie istotne:
- OpenAI używa
OAI-SearchBotdo surfacowania stron w funkcjach wyszukiwania ChatGPT i oddziela go odGPTBot, który dotyczy potencjalnego dostępu do trenowania modeli. Są to niezależne ustawienia wrobots.txt. - Google stwierdza, że te same podstawy SEO pozostają istotne dla AI Overviews i AI Mode oraz że nie ma dodatkowych wymagań technicznych ani specjalnego znacznika schema.org potrzebnego do pojawienia się w tych funkcjach.
- Perplexity deklaruje, że
PerplexityBotrespektujerobots.txti że zablokowane treści nie są indeksowane ani używane do pre-treningu modeli fundacyjnych. llms.txtjest propozycją standardu opisaną przez jej autorów jako propozycja standaryzacji pliku pomagającego modelom LLM korzystać z informacji na stronie - nie jest potwierdzonym powszechnym wymogiem.
Niejasne pozostaje dokładne ważenie sygnałów, sposób w jaki dobór cytowań zmienia się w zależności od typu zapytania, wpływ personalizacji lub aktualności na selekcję źródeł oraz to, czy dane z grafów encji odgrywają bezpośrednią rolę. Właściwa strategia polega nie na pogoni za ukrytymi czynnikami rankingowymi, lecz na redukowaniu niejednoznaczności.
Framework AI Search Readiness Grupy Insight
W Grupie Insight oceniamy gotowość na AI Search w sześciu wymiarach: klarowność encji, architektura treści, dane strukturalne, autorytet tematyczny, sygnały zaufania i dostępność dla crawlerów.
Łącznie decydują one o tym, czy strona jest jedynie opublikowana - czy faktycznie użyteczna jako źródło dla systemów AI Search.
1. Definicja encji - bądź rozpoznawalny, zanim staniesz się wyszukiwalny
Pierwsze pytanie, jakie system AI zadaje w związku z Twoją marką, brzmi nie „jak to rankuje?", ale „czym to jest?"
Encja to nazwany, ustrukturyzowany fragment wiedzy: firma, osoba, usługa, lokalizacja. Jeśli Twoja marka nie jest konsekwentnie zdefiniowana na własnej stronie i w zaufanych zewnętrznych źródłach, systemy AI mają mniej kontekstu do zrozumienia, kim jesteś, co robisz i czy Twoje treści powinny być Ci przypisane.
Dla firmy usługowej klarowność encji oznacza, że ta sama nazwa firmy, kategorie usług, lokalizacje, profile kadry kierowniczej, imiona autorów i profile zewnętrzne tworzą jedną spójną narrację. Jeśli Twoja strona mówi jedno, strona LinkedIn mówi coś innego, a profile w katalogach używają nieaktualnych opisów — encja staje się niejednoznaczna.
Co zrobić:
- Stwórz dedykowaną stronę O nas, która definiuje firmę w kategoriach faktycznych: co robisz, komu służysz, gdzie działasz, kiedy powstałeś. Pisz tak jak redaktor Wikipedii - deklaratywnie, ze źródłami, jednoznacznie.
- Zadbaj o spójność nazwy, adresu, numeru telefonu (NAP) oraz kluczowych usług na stronie, w Google Business Profile, LinkedIn, Clutch i odpowiednich katalogach branżowych.
- Użyj schematu
Organizationz linkamisameAsdo wszystkich zweryfikowanych profili. - Zbuduj dedykowaną stronę dla każdego autora publikującego treści na Twojej stronie — z rolą, latami doświadczenia i linkami do obecności zewnętrznej.
W Grupie Insight traktujemy definicję encji jako fundament każdego projektu AI Search. Mechanikę widoczności opartej na encjach szczegółowo opisujemy w artykule Entity SEO w 2026: dlaczego marki wygrywają z keywordami. Najszybsze wzrosty widoczności, jakie obserwowaliśmy, wynikały nie z wolumenu treści, lecz ze spójnego i rozpoznawalnego prezentowania marki w różnych źródłach internetowych.
2. Architektura treści - struktura, którą AI może parsować
Dobrze ustrukturyzowane treści są łatwiejsze dla systemów AI do parsowania, wyodrębniania, podsumowywania i cytowania niż strony zdominowane przez prozę lub wizualnie złożone.
Krótka strona wypchana targetowanymi frazami daje systemowi AI bardzo mało kontekstu. Bardziej kompletna strona, która definiuje pojęcie, wyjaśnia jego mechanizm, porównuje alternatywy i odpowiada na pytania uzupełniające, jest zazwyczaj łatwiejsza do pobierania i podsumowywania.
Najbardziej użyteczne formaty treści:
- Paragrafy definicyjne - krótka, bezpośrednia odpowiedź na pytanie „czym jest X" na początku każdej sekcji. Pisz zdanie, które model mógłby zacytować dosłownie. Wyprzedź wniosek; rozwinięcie następuje po nim.
- Numerowane lub wypunktowane procesy - formaty krok po kroku z wyraźnymi nagłówkami są łatwe do wyodrębnienia. „Jak przenieść sklep WooCommerce do Headless Next.js w 5 krokach" jest bardziej pobieralne niż esej na ten temat.
- Sekcje FAQ z prawdziwymi pytaniami - nie „Co Was wyróżnia?", ale „Ile trwa wdrożenie AI SEO?" FAQ ustrukturyzowane za pomocą schematu FAQPage daje systemowi zarówno pytanie, jak i cytowalną odpowiedź w jednej, samowystarczalnej jednostce.
- Tabele porównawcze - ustrukturyzowane porównania są łatwe do wyodrębnienia i podsumowania. Jeśli Twoja kategoria usług obejmuje opcje lub kompromisy, przejrzysta tabela sprawdza się lepiej niż narracja.
Czego unikać:
- Ukrywania kluczowych informacji w PDF-ach, komponentach renderowanych przez JavaScript lub za bramkami logowania
- Niejasnych nagłówków sekcji, które nie sygnalizują treści poniżej
- Ścian tekstu bez podtytułów, definicji ani sygnałów strukturalnych
Przydatny test: czy możesz wyodrębnić kompletną, samodzielną odpowiedź na konkretne pytanie z każdej sekcji strony w mniej niż 60 słowach? Jeśli nie - sekcja jest zbyt słabo ustrukturyzowana pod kątem pobierania przez AI.
3. Schema markup - spraw, żeby strony były samo-opisujące
Dane strukturalne nie powodują bezpośrednio cytowań przez AI. Ale dają systemom jednoznaczne sygnały o tym, czym jest strona, kto ją stworzył i co opisuje — zmniejszając obciążenie interpretacyjne i zwiększając prawdopodobieństwo prawidłowego przypisania.
W przypadku Google AI Overviews i AI Mode Google stwierdza, że nie jest wymagany żaden specjalny znacznik schema.org, aby pojawiać się w tych funkcjach. Danych strukturalnych nie należy traktować jako skrótu do AI. Ich rola jest bardziej fundamentalna: pomagają uczynić maszynoczytelnym znaczenie strony, autorstwo, daty, organizację, okruszki nawigacyjne, produkty, usługi i FAQ — o ile odpowiadają widocznej treści na stronie.
Minimalne wymagane schema dla AI Search Readiness:
Organization- na stronie głównej i stronie O nas, zname,url,logo,sameAs,contactPointWebPage/Article- na każdej stronie z treścią, zauthor,datePublished,dateModifiedPerson- na każdej stronie z biogramem autora, z linkami zwrotnymi do opublikowanych artykułówFAQPage-na stronach usługowych i artykułach długoformowych z sekcjami Q&ABreadcrumbList- globalnie na całej stronie
Dla firm usługowych: dodaj LocalBusiness lub ProfessionalService, Service na poszczególnych stronach usługowych oraz Review, jeśli masz zagregowane opinie.
Celem nie jest gromadzenie typów schematów. Szczegółowe omówienie tego, jak dane strukturalne działają w środowiskach AI Search, znajdziesz w artykule Dane strukturalne w erze AI Search. Celem jest sprawienie, żeby każda ważna strona była samo-opisująca — tak aby system mógł odpowiedzieć na pytanie „kto to opublikował, kiedy i na jaki temat" bez parsowania prozy.
4. Autorytet tematyczny — zdobądź kategorię, nie tylko słowo kluczowe
W praktyce izolowane strony rzadko wystarczają do budowania trwałej widoczności. Pojedynczy artykuł może odpowiedzieć na jedno pytanie, ale klaster treści daje zarówno użytkownikom, jak i maszynom więcej kontekstu: definicje, porównania, przewodniki wdrożeniowe, FAQ, case studies i strony usługowe połączone wokół jednej kategorii.
Na przykład klaster AI Search Optimization nie powinien składać się z jednego artykułu zatytułowanego „AI SEO". Powinien zawierać strategiczny framework, przewodnik techniczny, artykuł o entity SEO, artykuł o danych strukturalnych, przewodnik po pomiarach, przypadki użycia z branży oraz stronę usługową wyjaśniającą, jak praca jest realizowana.
Jak budować autorytet tematyczny pod AI Search:
- Zaplanuj klaster treści wokół swojej kluczowej kategorii usług — minimum 5–10 elementów
- Linkuj wewnętrznie w obrębie klastra, używając opisowych anchor textów — nie „kliknij tutaj" ani „czytaj więcej"
- Publikuj w stałym rytmie — klaster ostatnio aktualizowany w 2022 roku sygnalizuje stagnację niezależnie od pierwotnej jakości
- Używaj linków wewnętrznych wzmacniających relacje encji: autor → artykuł, usługa → case study, FAQ → artykuł
Strategia treści Grupy Insight pod AI Search opiera się w całości na klastrach. Artykuły opublikowane w Q1 i Q2 2026 roku — o danych strukturalnych, entity SEO i pomiarze widoczności w AI Search — tworzą jeden pobieralny klaster, który wzmacnia spójną pozycję marki w powiązanych tematach. Żaden artykuł nie jest zaprojektowany jako samodzielny.
5. Sygnały zaufania — udowodnij, że za treścią stoi ekspert
E-E-A-T pochodzi z Google Search Quality Rater Guidelines. Nie należy go opisywać jako bezpośredniego czynnika rankingowego ani potwierdzonego sygnału cytowania przez AI. Jest jednak użytecznym frameworkiem do oceny, czy treść jest łatwa do zaufania, weryfikacji i przypisania.
W kontekście AI Search ta sama logika ma zastosowanie: strona z nazwanym autorem, wyraźną odpowiedzialnością redakcyjną, aktualnymi źródłami, transparentnymi datami i weryfikowalną ekspertyzą jest łatwiejsza do oceny niż anonimowa, niepoparta treść — zarówno dla użytkowników, jak i systemów.
Praktyczna lista kontrolna:
- Każdy artykuł ma nazwanego autora z podlinkowanym biogramem
- Biogramy autorów wymieniają kwalifikacje, lata doświadczenia i linki do obecności zewnętrznej (LinkedIn, wywiady, wystąpienia na konferencjach)
- Artykuły powołują się na nazwane źródła, narzędzia i dane — nie na niejasne „badania wskazują" czy „eksperci zgadzają się"
- Wyraźna nota redakcyjna wyjaśnia podstawy stawianych twierdzeń i kiedy artykuł był ostatnio aktualizowany
- Strona była cytowana lub linkowana przez rozpoznawalne zewnętrzne źródła w branży
We własnych wdrożeniach często obserwujemy silniejsze wzorce widoczności, gdy marka łączy wyraźne sygnały encji z ukierunkowanym klastrem treści. Należy traktować to jako zaobserwowany wzorzec, nie publiczną regułę rankingową: jakość treści ma znaczenie, ale sama treść rzadko wystarcza, gdy marka stojąca za nią jest trudna do zidentyfikowania, zweryfikowania lub przypisania.
6. Dostępność techniczna - udostępnij treść crawlerom AI Search
Widoczność w AI Search zaczyna się od dostępu. Jeśli system nie może crawlować, pobierać ani interpretować Twoich treści, nie może ich wiarygodnie cytować.
Ale nie każdy crawler AI ma ten sam cel.
OpenAI rozdziela crawlowanie na potrzeby wyszukiwania od crawlowania na potrzeby trenowania modeli. OAI-SearchBot jest powiązany z odkrywaniem i cytowaniem w ChatGPT Search, podczas gdy GPTBot jest kontrolowany oddzielnie w kontekście potencjalnego dostępu do trenowania modeli. To rozróżnienie ma znaczenie: zezwolenie na pojawienie się treści w AI Search i zezwolenie na wykorzystanie treści do trenowania modeli to nie ta sama decyzja strategiczna.
Dokumentacja Perplexity stwierdza, że PerplexityBot respektuje robots.txt i że zablokowane treści nie są indeksowane ani używane do pre-treningu modeli fundacyjnych.
Lista kontrolna audytu technicznego:
- Sprawdź
robots.txti potwierdź, żeOAI-SearchBotiPerplexityBotnie są zablokowane, jeśli Twoim celem jest widoczność w AI Search - Oceń
GPTBotoddzielnie, jeśli Twoja organizacja ma politykę dotyczącą dostępu do danych treningowych - Zweryfikuj, że kluczowe treści są dostępne jako indeksowalne HTML — nie ukryte za interfejsami opartymi na JavaScript, bramkami logowania ani niedostępnymi komponentami
- Zadbaj o czystość i spójność kanonicznych URL-i — zduplikowane lub sprzeczne URL-e tworzą niejednoznaczność w pobieraniu
- Monitoruj Core Web Vitals i doświadczenie strony — wydajność nadal ma znaczenie, ponieważ techniczne SEO, crawlowalność i UX pozostają częścią szerszej warstwy wykrywalności
- Rozważ wdrożenie
llms.txtjako eksperymentalnej warstwy AI Readiness — nie ma obecnie zweryfikowanych publicznych dowodów na to, że jest powszechnym wymogiem widoczności w ChatGPT Search, Google AI Overviews ani Perplexity. Najlepiej wdrażać go obokrobots.txt,sitemap.xml, schema markup i silnego linkowania wewnętrznego — nie jako ich zamiennik
Co sprawia, że treści są bardziej użyteczne dla AI Search — i co zazwyczaj ma małą wartość
Bardziej użyteczne:
- Jasne, deklaratywne zdania na początku sekcji
- Nazwani autorzy z weryfikowalnymi kwalifikacjami
- Spójna obecność encji marki w internecie
- Głębia i szerokość tematyczna zamiast powierzchownego pokrycia
- Dane strukturalne odpowiadające widocznej treści
- Świeże, regularnie aktualizowane treści z wyraźnymi datami publikacji i modyfikacji
- Twierdzenia poparte źródłami, przykłady i szczegóły wdrożeniowe
Zazwyczaj o małej wartości:
- Częstotliwość i zagęszczenie słów kluczowych
- Meta keywords
- Linki niskiej jakości z nieistotnych domen
- Dekoracyjne podtytuły, które nie wyjaśniają sekcji
- Treści ukryte w karuzelach, zakładkach lub komponentach zależnych od JavaScript
- Anonimowe lub nieprzypisane publikacje
- Generyczne treści AI bez oryginalnego doświadczenia, przykładów ani dowodów
Rola oryginalnego doświadczenia
Systemy AI Search nie potrzebują kolejnego ogólnego wyjaśnienia tego samego tematu. Potrzebują źródeł, które wnoszą coś konkretnego: szczegóły wdrożeniowe, przetestowane workflow, prawdziwe przykłady, dane, case studies lub ekspercką interpretację.
Dla firmy usługowej oryginalne doświadczenie może przyjąć kilka form:
- przykłady przed i po wdrożeniu
- zrzuty ekranu z audytów lub raportów analytics
- zanonimizowane wzorce klientów
- decyzje techniczne i kompromisy
- błędy odkryte podczas rzeczywistych projektów
- praktyczne listy kontrolne używane przez zespół wdrożeniowy
Tu właśnie eksperckie treści stają się trudne do skopiowania. Definicje może przepisać każdy. Oryginalnego doświadczenia — nie.
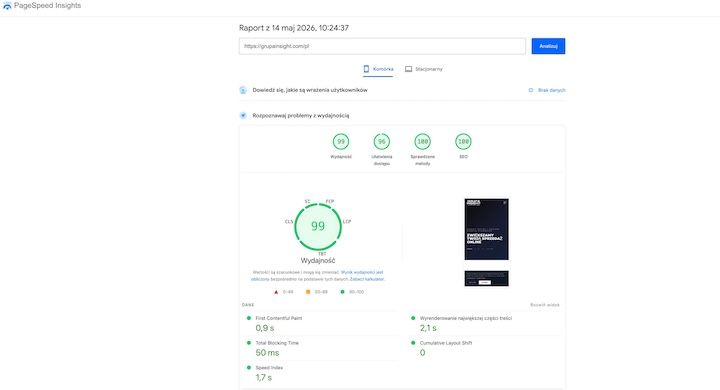
Własna strona Grupy Insight osiąga wynik 99/100 w PageSpeed Insights na urządzeniach mobilnych, z LCP na poziomie 2,1 s i CLS równym 0 w przeprowadzonym teście. Nie prezentujemy tego jako sygnału rankingowego AI. Prezentujemy to jako dowód, że te same standardy techniczne, które rekomendujemy klientom, są wdrożone na naszej własnej stronie.
[Zrzut ekranu: PageSpeed Insights — grupainsight.com, mobile, Performance 99 / Accessibility 96 / Best Practices 100 / SEO 100, maj 2026]
Jak sprawdzić, czy AI Search faktycznie widzi Twoją markę
Pomiar widoczności w AI Search jest niedoskonały — i właśnie dlatego potrzebujesz punktu bazowego.
W przeciwieństwie do klasycznego SEO, AI Search nie daje stabilnych pozycji rankingowych, czystych danych o wyświetleniach ani uniwersalnego dashboardu analytics. To samo zapytanie może dawać różne odpowiedzi w zależności od kontekstu, lokalizacji, personalizacji, aktualności i używanego systemu.
Nie oznacza to, że pomiar jest niemożliwy. Oznacza, że trzeba mierzyć wzorce widoczności zamiast stałych pozycji.
Cztery rzeczy do sprawdzenia teraz:
- Ruch referralowy z chatgpt.com — otwórz platformę analytics i przefiltruj źródła referralowe. OpenAI stwierdza, że wydawcy, którzy zezwalają na
OAI-SearchBot, mogą śledzić ruch referralowy z ChatGPT, ponieważ ChatGPT automatycznie dodajeutm_source=chatgpt.comdo referralowych URL-i. - Trendy zapytań brandowych w Google Search Console — przefiltruj wyświetlenia i kliknięcia dla nazwy swojej marki. Rosnący trend w zapytaniach brandowych często wskazuje na rosnącą świadomość marki, do której może przyczyniać się ekspozycja w AI — nawet gdy nie jest rejestrowane żadne kliknięcie.
- Miesięczne testy promptów — uruchamiaj stały zestaw zapytań w ChatGPT, Perplexity i Google Search, które mogą uruchamiać AI Overviews, co miesiąc. Testuj nazwę marki, kluczowe usługi i porównania konkurencyjne. Dokumentuj, czy się pojawiasz, kto jest cytowany zamiast Ciebie i do jakich źródeł odwołuje się AI.
- Weryfikacja przypisania źródła — gdy pojawiasz się w odpowiedziach AI, sprawdź, czy system cytuje Twoje własne strony, wzmianki o Twojej marce od stron trzecich (katalogi, prasa, recenzje) lub żadne z nich. To mówi Ci, czy pracuje Twoja własna treść, czy Twój footprint encji.
Śledź to co miesiąc. Pełną metodologię pomiaru znajdziesz w artykule Jak mierzyć widoczność w AI Search w 2026. Celem jest prosty punkt bazowy widoczności — nie złożony dashboard — który mówi Ci, czy działania optymalizacyjne przynoszą efekty.
Praktyczna mapa drogowa: pierwsze 90 dni
Dni 1–30 — Zapewnij dostępność i atrybucję strony
- Przeprowadź audyt
robots.txt, reguł CDN i ustawień WAF pod kątem crawlerów AI wyszukiwania, takich jakOAI-SearchBotiPerplexityBot - Oceń
GPTBotoddzielnie, jeśli Twoja organizacja ma politykę dotyczącą dostępu do danych treningowych - Zweryfikuj, że kluczowe strony usługowe, artykuły, case studies i strony autorów są dostępne jako indeksowalne HTML
- Wdróż lub popraw schematy
Organization,Person,Article,WebPage,BreadcrumbListi odpowiednieService - Zaktualizuj przypisanie autorów, daty publikacji i noty redakcyjne
- Stwórz wstępny punkt bazowy widoczności AI za pomocą brandowanych promptów, promptów usługowych i sprawdzenia ruchu referralowego
Dni 31–60 — Buduj klarowność encji i treści
- Przepisz kluczowe strony usługowe z bezpośrednimi paragrafami definicyjnymi, przypadkami użycia, sekcjami procesu, FAQ i blokami porównawczymi
- Stwórz lub ulepsz strony O nas, autorów, usług i case studies
- Ujednolić opisy firmy w LinkedIn, Google Business Profile, katalogach, profilach partnerów i branżowych bazach danych
- Opublikuj lub zaktualizuj jeden artykuł filarowy w klastrze AI Search
- Dodaj linki wewnętrzne między usługami, artykułami, case studies i stronami autorów
Dni 61–90 — Buduj autorytet tematyczny i pomiar
- Publikuj artykuły wspierające wokół głównej kategorii: entity SEO, dane strukturalne, pomiar widoczności AI, ChatGPT Search, Google AI Overviews i branżowe przypadki użycia
- Uruchamiaj miesięczne testy widoczności w ChatGPT, Perplexity i zapytaniach Google Search, które mogą uruchamiać odpowiedzi AI Overviews lub AI Mode
- Porównuj cytowane źródła z własnymi stronami i wzmiankami stron trzecich
- Używaj analytics, GSC i ręcznych testów promptów do oceny, czy widoczność się poprawia
- Przekształć wyniki w raport AI Search Readiness i backlog wdrożeniowy — pełna metodologia pomiaru jest opisana w artykule Jak mierzyć widoczność w AI Search w 2026
Okno konkurencyjne jest nadal otwarte
Optymalizacja pod AI Search jest wciąż niedojrzałą dyscypliną. Wiele agencji mówi o GEO lub LLM SEO, ale niewiele marek przeprowadziło poważny audyt klarowności encji, dostępu crawlerów AI, danych strukturalnych, architektury treści i pomiaru widoczności AI.
Ta luka się zamknie. Marki, które teraz budują obecność encji, ustrukturyzowane treści i autorytet tematyczny, zachowają tę przewagę w miarę jak AI Search zwiększa swój udział w całości zapytań.
Fundament techniczny nie jest złożony. Inwestycja w treści nie jest duża. Wymaga jasnego frameworku i konsekwentnego wdrożenia - i zaczęcia przed zamknięciem okna.
Chcesz wiedzieć, czy Twoja marka jest widoczna w AI Search?
Grupa Insight realizuje audyty AI Search Readiness dla marek, które chcą zrozumieć, czy ich strony są odkrywalne, przypisywalne i cytowalne w ChatGPT Search, Google AI Overviews i AI Mode, Perplexity i innych środowiskach AI Search.
Audyt obejmuje klarowność encji, dane strukturalne, architekturę treści, dostępność dla crawlerów, sygnały zaufania, testy widoczności AI i priorytetową mapę drogową wdrożenia.
Zobacz, jak wygląda optymalizacja pod AI Search w praktyce →
Najczęściej zadawane pytania
Czy możecie zagwarantować widoczność w ChatGPT Search? Nie. Nie istnieje publiczny mechanizm gwarantujący włączenie lub cytowanie w ChatGPT Search. Optymalizacja pod AI Search zwiększa prawdopodobieństwo, że Twoje treści mogą być odkryte, zinterpretowane, uznane za wiarygodne i zacytowane w odpowiednim kontekście — ale żadna agencja nie może uczciwie gwarantować pojawienia się w każdej odpowiedzi AI.
Czy powinienem zezwolić na GPTBot, jeśli chcę pojawiać się w ChatGPT Search?
Niekoniecznie. OpenAI oddziela OAI-SearchBot, powiązanego z odkrywaniem w wyszukiwaniu ChatGPT Search, od GPTBot, który dotyczy potencjalnego dostępu do trenowania modeli. Jeśli Twoim celem jest widoczność w ChatGPT Search, najpierw oceń OAI-SearchBot. Decyzję o GPTBot podejmij oddzielnie na podstawie polityki Twojej organizacji wobec dostępu do danych treningowych.
Czy llms.txt jest wymagany dla AI Search?
Nie. llms.txt nie jest potwierdzonym powszechnym wymogiem widoczności w AI Search. Najlepiej traktować go jako eksperymentalny plik pomocniczy opisujący najbardziej autorytatywne treści. Należy go wdrażać obok silniejszych fundamentów: crawlowalności, sitemap.xml, schema markup, linków wewnętrznych i przejrzystej architektury treści — nie jako ich zamiennik.
Czy optymalizacja pod AI Search różni się od SEO? Tak, ale nie jest od niego oddzielna. Optymalizacja pod AI Search bazuje na technicznym SEO, ustrukturyzowanych treściach, crawlowalności, linkowaniu wewnętrznym, doświadczeniu strony i pomocnych treściach. Różnica polega na akcencie: AI Search wymaga silniejszej klarowności encji, atrybucji źródeł, struktury treści i pobieralności, ponieważ systemy często podsumowują i cytują fragmenty zamiast po prostu rankować strony na liście.
Jak mierzycie widoczność w AI Search? Widoczność w AI Search mierzy się przez kombinację analizy ruchu referralowego, weryfikacji przypisania źródeł, brandowanych i niebrandowanych testów promptów, trendów w Google Search Console oraz monitorowania cytowań w ChatGPT, Perplexity i Google AI Overviews. Nie jest to tak czyste jak klasyczne śledzenie pozycji, dlatego celem jest mierzenie wzorców widoczności w czasie, nie stałych pozycji.
Czy ChatGPT Search używa tych samych sygnałów co Google? Jest istotne pokrycie — jakość treści, wyraźna struktura i autorytatywność mają znaczenie w obu systemach — ale mechanizmy się różnią. Klasyczne wyszukiwanie rankuje strony na liście; AI Search wybiera i podsumowuje źródła przydatne do odpowiedzi na konkretne pytanie. Schema markup, spójność encji i klarowność treści wydają się mieć większe znaczenie w AI Search niż surowy autorytet linkowy, choć dokładne ważenie nie jest publicznie udokumentowane.
Czy mała strona może być cytowana w ChatGPT Search? Tak, ale nie dlatego, że rozmiar przestaje mieć znaczenie. Mniejsza strona może stać się użytecznym źródłem, gdy wyraźnie omawia konkretny temat, dostarcza oryginalnego doświadczenia, jest technicznie dostępna i prezentuje silne sygnały encji i zaufania. W niszowych kategoriach B2B lub usług profesjonalnych głębia i specyficzność mogą pomóc mniejszej stronie konkurować z szerszymi, mniej ukierunkowanymi źródłami.
Źródła
- OpenAI — Bots and Crawlers Documentation: dokumentacja
OAI-SearchBot,GPTBoti niezależnych ustawień robots.txt dla widoczności w wyszukiwaniu i dostępu do trenowania modeli. platform.openai.com/docs/bots - OpenAI — Publishers and Developers FAQ: wskazówki dotyczące pojawiania się w wynikach wyszukiwania ChatGPT i śledzenia ruchu referralowego z ChatGPT przez
utm_source=chatgpt.com. help.openai.com - Google Search Central — AI Features and Your Website: wskazówki dotyczące AI Overviews, AI Mode, podstaw SEO, wymagań technicznych, danych strukturalnych i raportowania w Search Console. developers.google.com
- Google Search Central — Creating Helpful, Reliable, People-First Content: wskazówki dotyczące pomocnych treści i E-E-A-T zgodnie z Search Quality Rater Guidelines. developers.google.com
- Perplexity — How does Perplexity follow robots.txt?: wskazówki dotyczące
PerplexityBot, obsługi robots.txt, ograniczeń indeksowania zablokowanych stron i kwestii trenowania modeli. perplexity.ai - llms.txt — The /llms.txt File: oryginalna propozycja standaryzacji pliku LLM-readable z wytycznymi dla strony. llmstxt.org
Artykuł został opracowany przez zespół SEO & AI Grupy Insight na podstawie praktycznych wdrożeń u klientów i własnych projektów AI Readiness agencji. Twierdzenia techniczne odzwierciedlają zaobserwowane wzorce i publicznie dostępną dokumentację OpenAI, Google i Perplexity według stanu na Q2 2026. Tam gdzie cytowana jest oficjalna dokumentacja, linki znajdują się w sekcji Źródła. Specyfikacja llms.txt jest opisana przez jej autorów jako propozycja standaryzacji. Ostatnia aktualizacja: maj 2026.
— Polityka redakcyjna i źródła